Vue -- docxtemplater一键生成docx文档
一、起因
最近遇到一个新需求,是需要系统导出word文档,内容包含echarts、图片等。
一般系统导出excel、word文档这些活都是后端来进行处理,前端只需要接收文件下载即可,毕竟后端有很多成熟的库和封装过的方法可以轻松实现。可惜公司这边又有新项目来,急需人手,导致后端人员木有很多时间。
SO,既然如此,那咱们前端自己上,重拳出击🤜 冲冲冲!!
二、docxtemplater简介
通过不断的走访调查(baidu,google,github),终于发现了一款强大的插件docxtemplater,且在github上拥有2.6k star数。
docxtemplater的运行方式和 Mustache模板引擎非常类似,都是提供一个模板,里面添加制定嵌入标记
{ },docxtemplater通过识别这些嵌入标记,将我们需要的数据渲染到模板上面。docxtemplater不单单可以处理docx文件还可以处理pptx文件。
docxtemplater是一个收费的库,但是它拥有免费的开源版本,对于当前系统的业务要求,使用免费版本完全可以解决。
三、使用教程
1、依赖安装
npm install docxtemplater --save // 接收docx模板并根据标签进行数据替换 版本3.37.13
npm install pizzip --save // 处理docx模板 版本3.1.4
npm install file-saver --save // 处理输出文件 版本2.0.5
npm install docxtemplater-image-module-free --save // 处理docx文件显示照片 版本1.1.1docxtemplater:用于处理预先写好的docx、excel、pptx等文件模板,生成对应的数据文件。
pizzip:是一个可以创建以及提取zip文件的JS库,允许在浏览器环境中动态的生成zip文件,并可以对其进行更新、删除、压缩、解压等操作。(docx文件是基于Open XML格式的zip文件,所以也可以被同样处理)
file-saver:同样也是一个JS库,提供在浏览器环境中保存文件的功能,且FileSaver.js 提供了简单而直观的 API,使得在浏览器环境中实现文件下载和保存变得容易。它兼容各种现代浏览器,并支持大多数常见的文件类型,如文本文件、图像文件、PDF 等。
docxtemplater-image-module-free:免费开源的库,用于处理docxtemplater生成图片的功能,因为docxtemplater是一个收费的库,只提供像循环、判断等基础的语法文字展示,而对于像图片、HTML语法的解析等都是需要收费滴。
2、docxtemplater标签以及基本语法
通过在word模板文档定义{str}、{#loop} {/loop}、{#img}等标签,使用docxtemplater中的setData({ str: '你好',... })方法为文档设置数据。这些数据将在模板中以占位符的形式被替换。例如,模板中的"{str}"将被"你好"替换,其他属性也会类似替换。
(1). 变量替换
通过在word文档中定义
{name}标签// test.docx 你好,我是{name}
在代码中,使用docxtemplater中的setData({ name: 'TKEY' })方法替换word文档中定义的标签,并显示定义的
name数据//test.docx 你好,我是TKEY
(2). 条件判断
条件判断通常是使用
{#condition}作为开始,{/condition}作为语句结束的判断,不过免费版有个缺点就是只能通过属性的是否有值,true和false来判断,其他例如三元表达式、数组.length判断等等免费版docxtemplater都无法进行判断。如:以
{#age}为判断条件,当age有值时就会直接显示:今年18岁了//test.docx 你好,我是{name} {#age}今年{age}岁了{/age}
定义setData()里的JSON数据
datalet data = { name: 'TKEY', age: '18' } const doc = new Docxtemplater(zip) doc.setData(data)最终生成的docx文件是:
//test.docx 你好,我是TKEY 今年18岁了
(3).循环语句
循环语句也是通过
{#loop}作为开始,{/loop}作为循环语句结束的判断,但对应的变量应为Array数据类型,如:定义
web属性,且其数据类型是数组对象,内容包含了web_name网站名称以及web_url网站路由地址//test.docx 你好,我是{name} {#age}今年{age}岁了{/age} {#web} 我的{web_name}网站:{web_url} {/web}
对于数组循环语句也有额外的条件判断,相当于
if与else,如:当数组为空时,我想在word文档中展示其他数据或者显示一个无博客字,就需要在循环语句
{#web}的下面定义{^web}//test1.docx 你好,我是{name} {#age}今年{age}岁了{/age} {#web} 我的{web_name}网站:{web_url} {/web} {^web} // else条件 无博客 {/web}
定义setData()里的JSON数据
data// test.docx let data = { name: 'TKEY', age: '18', web:[ { web_name: '情绪树洞', web_url: 'http://aurora.vikeya.com/' }, { web_name: '博客', web_url: 'https://vikeya.com/' }, ] } const doc = new Docxtemplater(zip) doc.setData(data) // test1.docx 当web数组为空时,展示的数据 let data1 = { name: 'TKEY', age: '18', web:[] } const doc1 = new Docxtemplater(zip) doc1.setData(data)导出docx文档结果如下:
//test.docx 你好,我是TKEY 今年18岁了 我的情绪树洞网站:http://aurora.vikeya.com/ 我的博客网站:https://vikeya.com/ //test1.docx 你好,我是TKEY 今年18岁了 无博客
(4).图片
图片使用
{%image}在word文档中进行标注即可,对于图片的数据传入需要特殊处理,后面的部分会进行介绍。
(5). HTML标签
要想使用HTML来渲染word文档,只需要在word文档中定义
{~~html}即可,再通过设置let data ={ html:'<div>你好</div>' }即可渲染。不过!docxtemplater对于HTML标签的渲染是需要收费滴,所以不做过多介绍辣~~
3、使用流程
创建一个word模板文档,将其放在public文件夹中(public/test.docx)
使用
PizZipUtils.getBinaryContent(url, callback);方法获取你的word文档,并将其解析成二进制文件。url:word文档的存放路径。callBack:返回一个 Promise 对象,可以使用它来处理获取到的二进制内容content。也可以使用 Promise 的 then 方法来处理成功返回的结果,在其中执行您想要的操作。
创建一个
PizZip对象:let zip = new PizZip(content),将模板文件的内容content加载到内存中进行解析。创建docxtemplater对象:
const doc = new Docxtemplater(zip),接受PizZip对象解析的模板内容进行处理。使用
doc.setData({ ... })方法渲染在word文档定义好的标签数据。使用
doc.render()渲染word模板文档。并使用
doc.getZip().generate()方法生成 Word 文档的 Blob 对象。然后,通过file-saver中的saveAs函数将 Blob 对象保存为名为"xxx.docx"的文件进行下载。
四、docxtemplater 完整代码实现
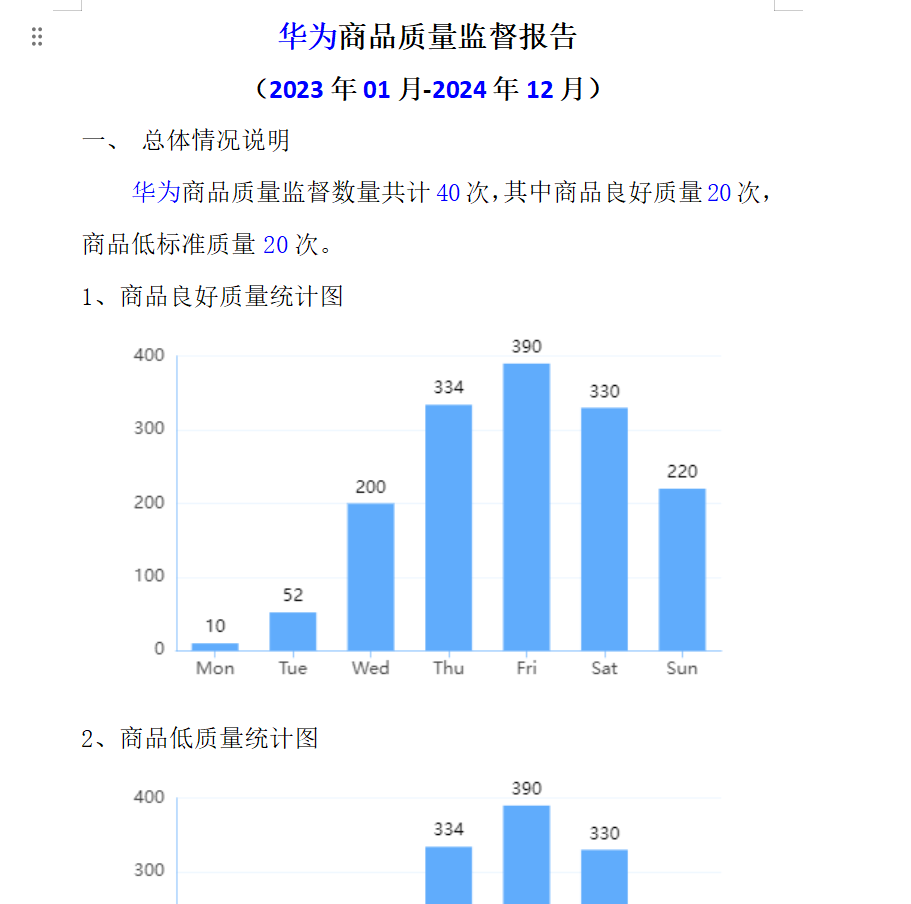
创建word文档test.docx,并使用对应的标签,如:

封装生成报告的组件。
<template> <div> <el-button type="success" size="default" @click="handleDownLoad" >生成报告</el-button > </div> </template> <script> import Docxtemplater from "docxtemplater"; import PizZip from "pizzip"; import PizZipUtils from "pizzip/utils/index.js"; import { saveAs } from "file-saver"; let ImageModule = require("docxtemplater-image-module-free"); // 读取你的doccx模板 获取二进制内容 function loadFile(url, callback) { PizZipUtils.getBinaryContent(url, callback); } export default { name: "docTemplate", methods: { handleDownLoad() { let that = this; // 读取模板 loadFile("./test/test.docx", function (error, content) { // 判断文件是否读取成功 是否有错误 if (error) { throw error; } // 针对图片处理 const opts = {}; opts.centered = true; // 图片居中,在word模板中定义方式为{%%image} opts.fileType = "docx"; // 将base64图片转化为二进制流 opts.getImage = (chartId) => { return that.base64DataURLToArrayBuffer(chartId); }; // 图片大小规格设置 opts.getSize = () => { return [500, 300]; }; // 将模板文件的内容加载到内存中进行解析 const zip = new PizZip(content); // 实例化docxtemplater const doc = new Docxtemplater(zip, { modules: [new ImageModule(opts)], // 使用图片模块 paragraphLoop: true, // 允许段落循环 linebreaks: true, // 允许换行 }); // 设置模板变量 let data = { platForm_name: "华为", start_year: "2023", start_month: "01", end_year: "2024", end_month: "12", observed_count: 40, high_count: 20, low_count: 20, echarts_report: [ { title: "1、商品良好质量统计图", image: "data:image/png;base64, xxxxx" }, { title: "2、商品低质量统计图", image: "data:image/png;base64,xxxxxxxxxxx" }, ], }; // 为word文档设置数据。这些数据将在模板中以占位符的形式被替换。 doc.setData(data); try { // docxtemplater渲染文件 doc.render(); } catch (error) { let e = { message: error.message, name: error.name, stack: error.stack, properties: error.properties, }; console.log(JSON.stringify({ error: e })); throw error; } // 获取文档的字节流并生成 Word 文档的 Blob 对象 const out = doc.getZip().generate({ type: "blob", mimeType: "application/vnd.openxmlformats-officedocument.wordprocessingml.document", }); // 通过file-saver中的saveAs函数将 Blob 对象保存为名为"xxx.docx"的文件进行下载。 saveAs(out, "output.docx"); }); }, /** * 下载图片什么需要将格式转化为base64 * 图片转base64方法 */ urlToBase64(url) { return new Promise((resolve) => { const image = new Image(); image.setAttribute("crossOrigin", "Anonymous"); image.onload = function () { const canvas = document.createElement("canvas"); canvas.width = image.width; canvas.height = image.height; canvas.getContext("2d").drawImage(image, 0, 0); const result = canvas.toDataURL("image/png"); resolve(result); }; image.src = url; }); }, /** * base64转ArrayBuffer */ base64DataURLToArrayBuffer(dataURL) { const base64Regex = /^data:image\/(png|jpg|jpeg|svg|svg\+xml);base64,/; if (!base64Regex.test(dataURL)) { return false; } const stringBase64 = dataURL.replace(base64Regex, ""); let binaryString; if (typeof window !== "undefined") { binaryString = window.atob(stringBase64); } else { binaryString = Buffer.from(stringBase64, "base64").toString("binary"); } const len = binaryString.length; const bytes = new Uint8Array(len); for (let i = 0; i < len; i++) { const ascii = binaryString.charCodeAt(i); bytes[i] = ascii; } return bytes.buffer; }, }, }; </script> <style> </style>生成文档如图所示: